FAIRness of WDCC - summary
Findability of WDCC Data
F1. (meta)data are assigned a globally unique and eternally persistent identifier.
The WDCC offers DataCite data publication for long-term archived data. Permanent access to published data is ensured via assigned DOIs and data and metadata remain unchanged. To be eligible for publication at WDCC, data has to meet defined quality requirements. The oldest data DOI which is still used today (Link) was registered for the WDCC on March 18, 2004.
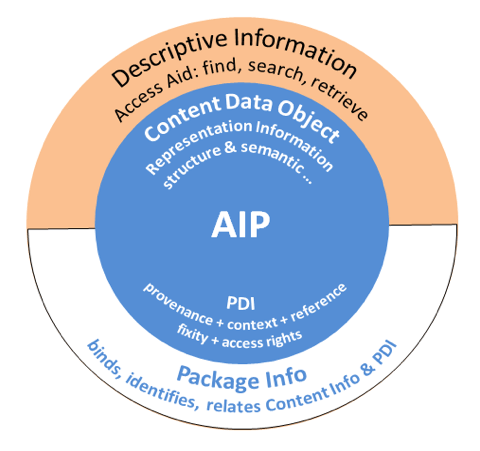
Fig. 1: A schematic depiction of the OAIS AIP used for the WDCC archival process.
The WDCC database contains the metadata (OAIS AIP, Figure 1 and 2) but also the data (OAIS AIP Content DataObject). DOIs are assigned at coarse granularity (experiments or dataset groups) of the internal WDCC organization hierarchy. Metadata are kept for all levels of the hierarchy. While all levels bear identifiers that are persistent, only the higher levels are assigned true DOIs.
Compliance: 90%
F2. data are described with rich metadata.
WDCC's metadata are stored in a relational database. Its tables are grouped in blocks concerning different themes. In addition, this data model is made up of several modules (table groups) which extend the basic information given in the blocks. After the (meta)data have reached the ‘completely archived’ state in the archiving process they are described with what WDCC refers to as "rich metadata" (OAIS AIPs are complete). During the DOI publication process, the metadata are extended with additional metadata e.g. accuracy and statistical reports (see Figure 3).
Compliance: 100%
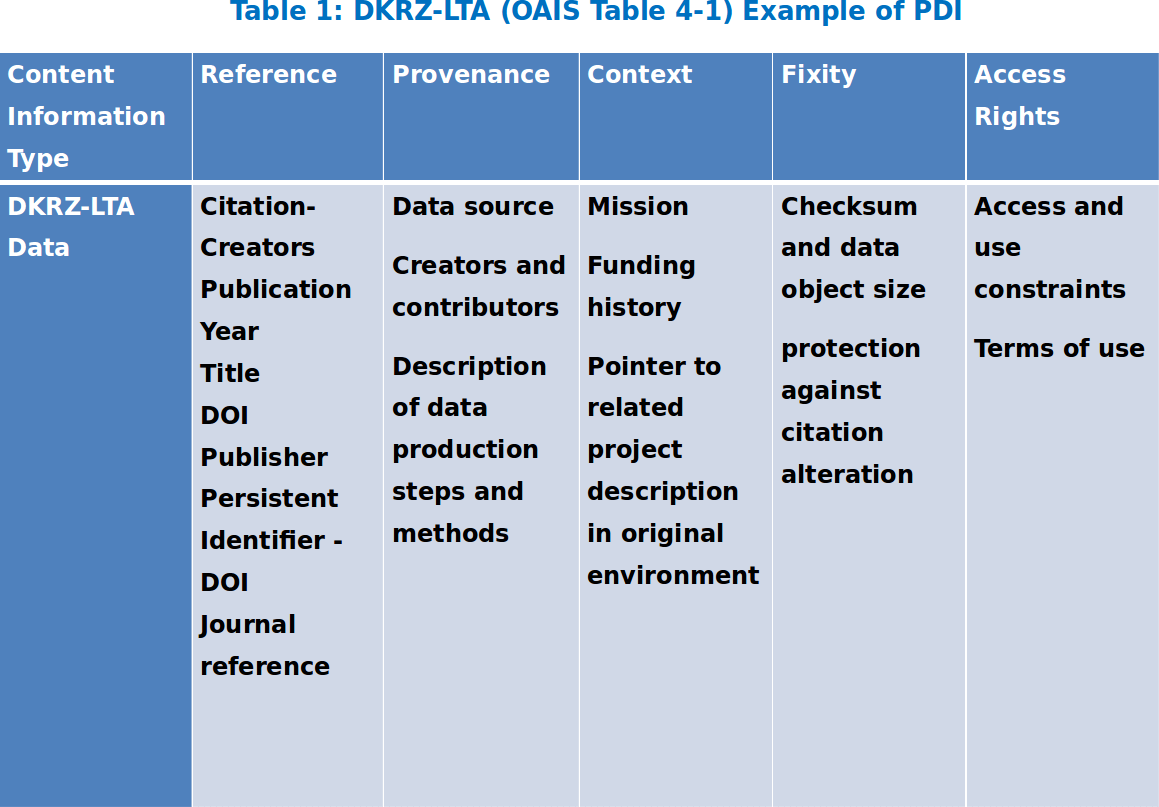
Fig. 2: Details of the PDI (Preservation Description Information) used in the OAIS AIP at WDCC.
F3. (meta)data are registered or indexed in a searchable resource.
All metadata records are available for external harvesters through an OAI PMH interface and a mapping to the Dublin Core, ISO 19135 and DataCite XML metadata sets. Important harvesters currently active are DWD-Gisc and WDS. Moreover, WDCC data with DOIs are visible in EUDAT B2FIND. Finally, the local WDCC GUI offers to search and browse.
Compliance: 100%
F4. metadata specify the data identifier.
Data at the coarse granularity levels which bear DOIs are described by metadata which also includes a reference to the assigned DOI. At the lower granularity levels, PIDs are currently not assigned. Some projects which are planned to be archived at WDCC will provide data where PIDs are assigned also at lower hierarchical levels. For these, PIDs are kept in the headers of data files and may also be kept within WDCC metadata. These procedures are not completely in place and while the relevant projects (CMIP6 in particular) are of high importance for the community, not all data at WDCC will follow these procedures yet.
Compliance: 50%
Fig. 3: Additional information required for archived datasets in the process of Data-Cite DOI-Publication at WDCC. The additional information ensure the re-usability of the data. Fig. 3: Additional information required for archived datasets in the process of Data-Cite DOI-Publication at WDCC. The additional information ensure the re-usability of the data.

Fig. 3: Additional information required for archived datasets in the process
of Data-Cite DOI-Publication at WDCC. The additional information ensure the
re-usability of the data.
Accessibility of WDCC Data
A1. (meta)data are retrievable by their identifier using a standardized communications protocol.
Metadata can be retrieved via OAI-PMH. Data can be retrieved by HTTP. The WDCC data organization allows for small data volumes per individual download.
Compliance: 100%
A1.1 the protocol is open, free, and universally implementable.
HTTP and OAI-PMH are open, free and universally implementable.
Compliance: 100%
A1.2 the protocol allows for an authentication and authorization procedure, where necessary.
Metadata is openly accessible. For data authentication is required with user account (http). The WDCC has published its terms of use.
Compliance: 100%
A2. metadata are accessible, even when the data are no longer available.
If data are lost or removed for any reason, remaining metadata remain available but can be changed. In particular, metadata may be modified to indicate the cause for their removal or loss.
Compliance: 100%
Interoperability of WDCC Data
I1. (meta)data use a formal, accessible, shared, and broadly applicable language for knowledge representation.
For all metadata there are Dublin Core, ISO 19135 and DataCite XML schema mappings which are openly accessible. Metadata instances can be retrieved via OAI-PMH. Data are using open format standards. The data model of the WDCC database is also publicly documented. There are however still cases where machine-interpretability of WDCC metadata may be improved by relying on more exhaustive ontologies and mappings to self-describing semantically enabled vocabularies and encodings.
Most data archived at WDCC conform to the data format CF-netcdf, which is in general self-describing and machine-readable and relies on commonly used controlled vocabularies, particularly the CF conventions. WDCC also archives other data formats, so not all data follow these conventions. There is no policy at WDCC to enforce this in order to not discourage users from depositing valuable scientific data. These data formats are archived as they are together with metadata but without provision of additional services.
Compliance: 80%
I2. (meta)data use vocabularies that follow FAIR principles.
CF–netcdf is publicly documented and openly accessible. To make the conventions citable via DOIs is an ongoing discussion within the CF committee.
Compliance: 100%
I3. (meta)data include qualified references to other (meta)data.
The relations possible to specify via the DataCite ‘relationType’ attribute are implemented in WDCC and are accessible from the WDCC web user interface and the harvesting interfaces. Users are supported in providing relations as relevant and possible for their data. However, data and metadata undergoing archival in WDCC may be more systematically linked with each other and with other relevant external knowledge, though this is naturally an open-ended task.
Compliance: 80%
Reusability of WDCC Data
R1. meta(data) have a plurality of accurate and relevant attributes.
In general, WDCC metadata contain rich information about the context in which data was generated, ensured by the metadata requirements for data submission. Specific items covered by WDCC metadata are relevant timestamps (creation and collection date), conditions under which data were created, actors involved in preparing the data, and model-related technical attributes such as model parameters and model descriptions.
There are specific limitations pertaining to the machine-interpretability of certain metadata aspects. In particular, data accuracy statements are currently not enforced to comply with standardization formalities due to their complexity, i.e., accuracy descriptions may be provided as free text.
Finally, metadata accuracy is controlled during the publication process by WDCC and DOI author.
Compliance: 80%
R1.1 (meta)data are released with a clear and accessible data usage license.
Metadata is released under CC0 universal license terms. The data licenses are dependent on the user. However, WDCC recommends using CC-by 4.0.
Compliance: 100%
R1.2 (meta)data are associated with their provenance.
WDCC metadata includes basic provenance information such as:
- Citation information: WDCC references DOI authors.
- The workflow that led to the data: WDCC project and experiment summary
- Who generated or collected it: DOI authors and contributors
Provenance information related to the workflow or procedures involved in generating data are described at a basic level with project and experiment summaries and accuracy reports. The level of detail is limited. Similarly, references to data from which archived data was derived from (and descriptions how it was derived) are currently limited to DataCite relationTypes and selected netcdf header information. The quality depends largely on the projects that generate data and request archival at WDCC.
Compliance: 80%
R1.3 (meta)data meet domain-relevant community standards.
Most metadata meet relevant community standards, in particular, CF-netcdf and the DataCite metadata kernel (cf. I1, I3). However, this may be project-dependent.
Compliance: 80%